Webディレクターのふるたです。
最近の案件でお世話になった「Grep置換」について紹介します。
お客様から既存サイトのファイル(HTML/CSS/Javascript など)一式をもらって、テストサーバにアップして自社のネットワークでサイトを再現する必要があったのですが、そのままでは画像、CSS、Javascriptのパスが通らず希望が叶いませんでした。
サイトを再現するには、相対パスで記述されている箇所すべてを、テストサーバの絶対パスに変換する必要がありました。
対象となるファイル数は、8,000以上!
というわけで、複数ファイルを対象に一括変換できるGrep置換が必要になったのです。
支給されたファイル群は下記のような構成でした。このファイル群をテストサーバにアップロードして、サイトを再現したい。
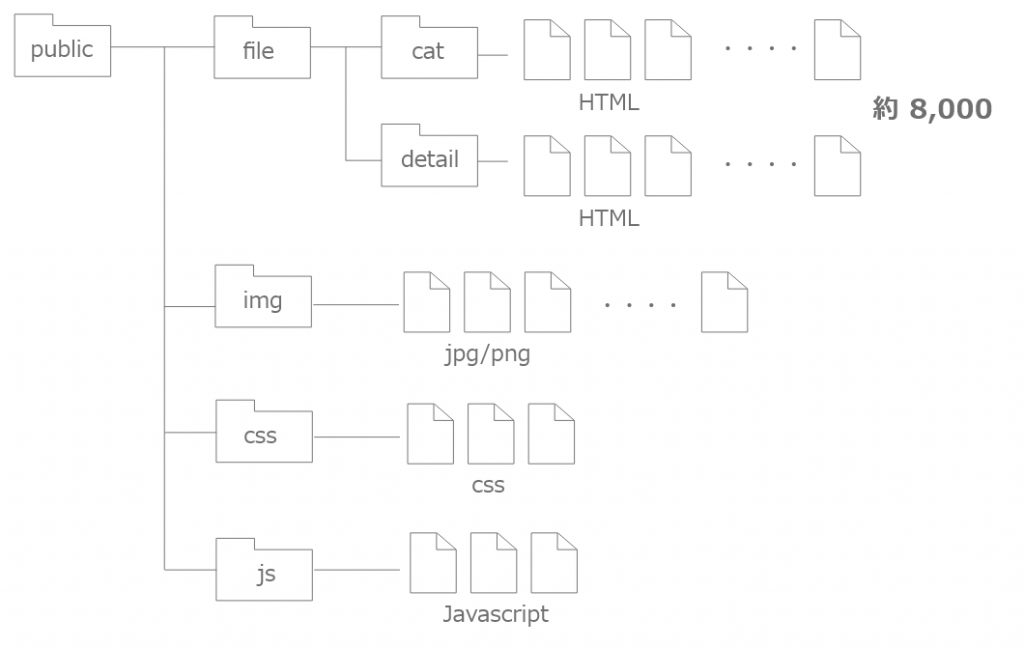
ただ、このままではテストサーバにアップロードしても、サイトを再現できませんでした。
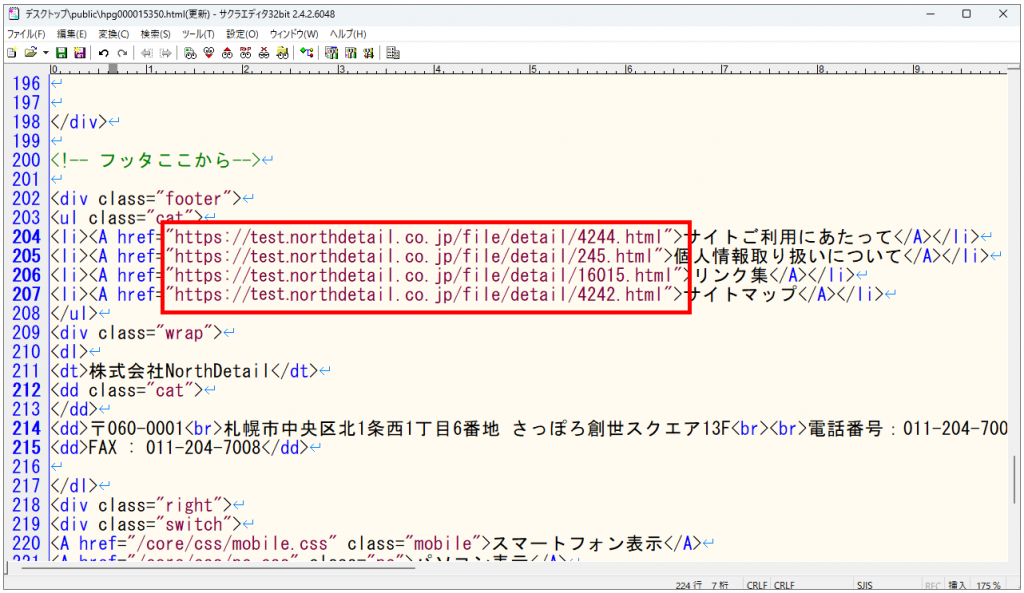
各HTMLファイル内にて、「相対パス」になっているコードを、絶対パスに置換したい。

↓下記のように「絶対パス」に書き換えたい

1種のHTMLファイルなら何の問題ないのですが、8,000種のファイルをすべて書き換えなければならない。
サクラエディタとは、日本製のWindows用テキストエディタで、GitHubよりダウンロードできます。フリーウェアとして配布されていて、長く多くの人に愛用されています。ただ、PCにインストールするときは自社のセキュリティポリシーを確認するなど自己責任でご利用ください。
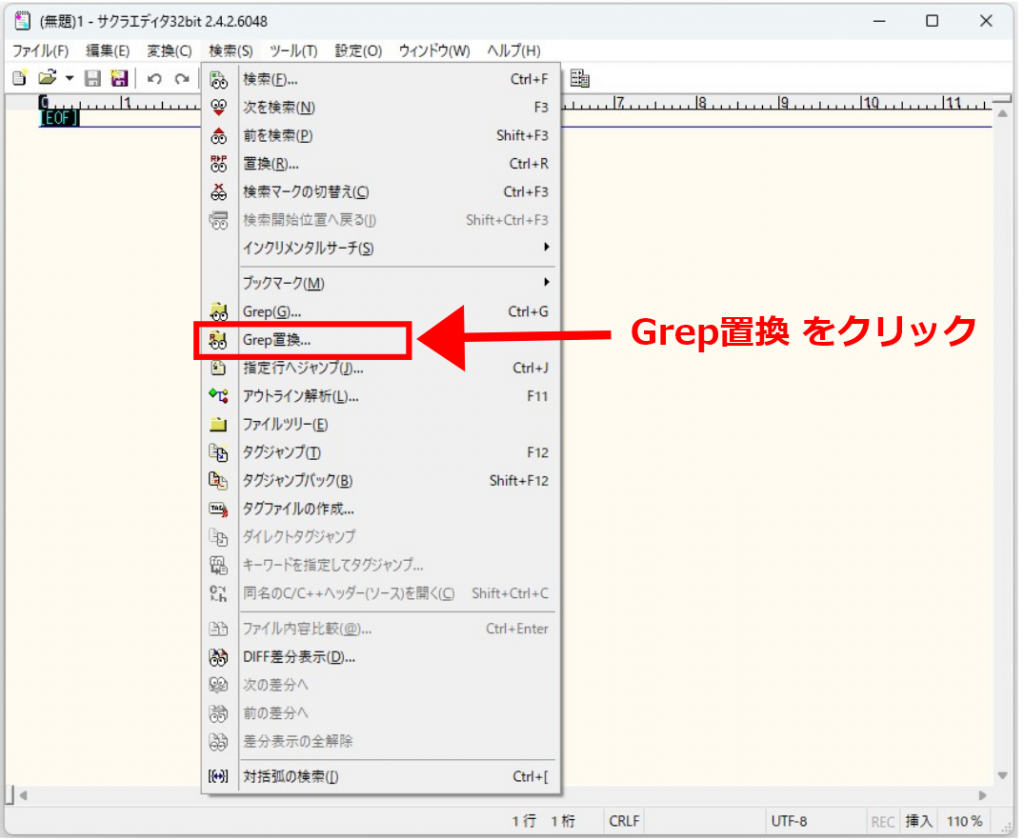
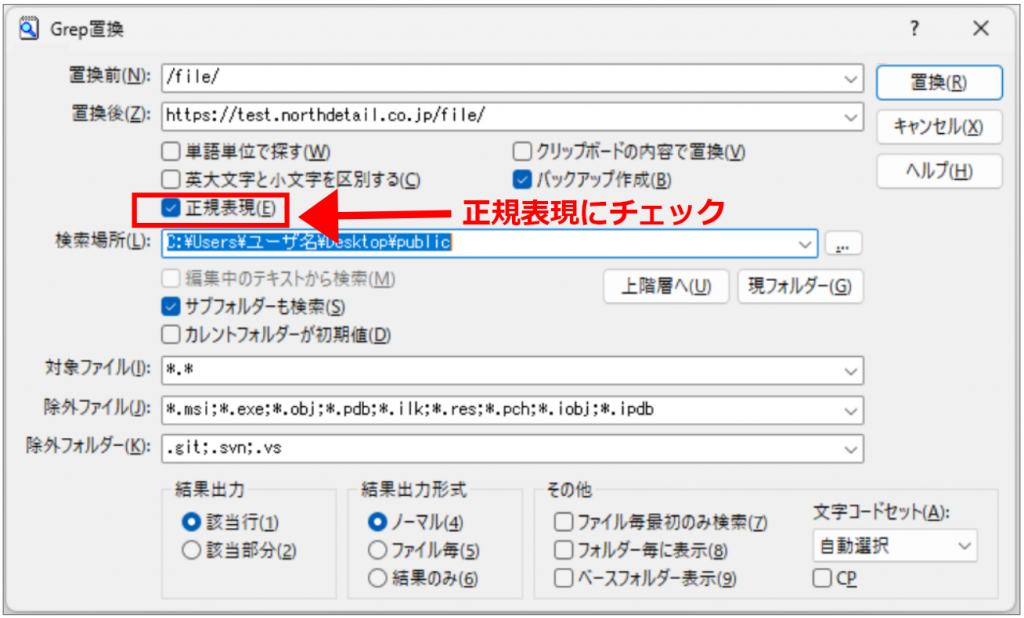
まずは、相対パス(/file/)を、絶対パス(https://test/northdetail.co.jp/file/)に変換することにします。
(1)置換前:「 /file/ 」を入力
(2)置換後:「 https://test/northdetail.co.jp/file/ 」を入力
(3)「バックアップ作成」にチェック ※念のため
(4)検索場所:ファイルがあるフォルダを選択
(5)「サブフォルダも検索」にチェック
※これによって、下層フォルダにあるHTMLファイルにも適用されます。
(6)「置換」をクリック
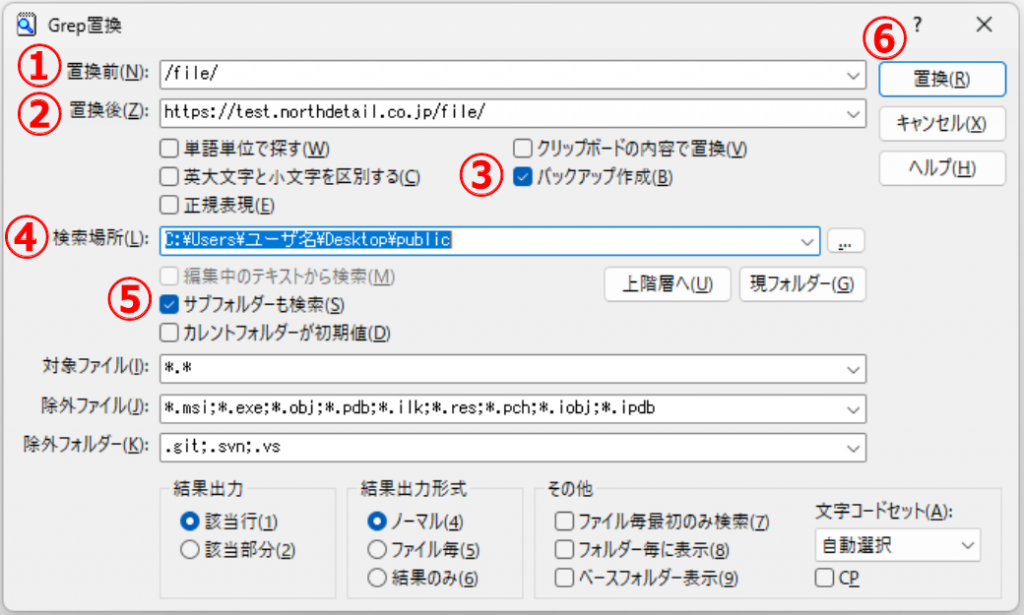
(7)エディタ画面にて、置換対象の「 /file/ 」が黄色にハイライトされます。
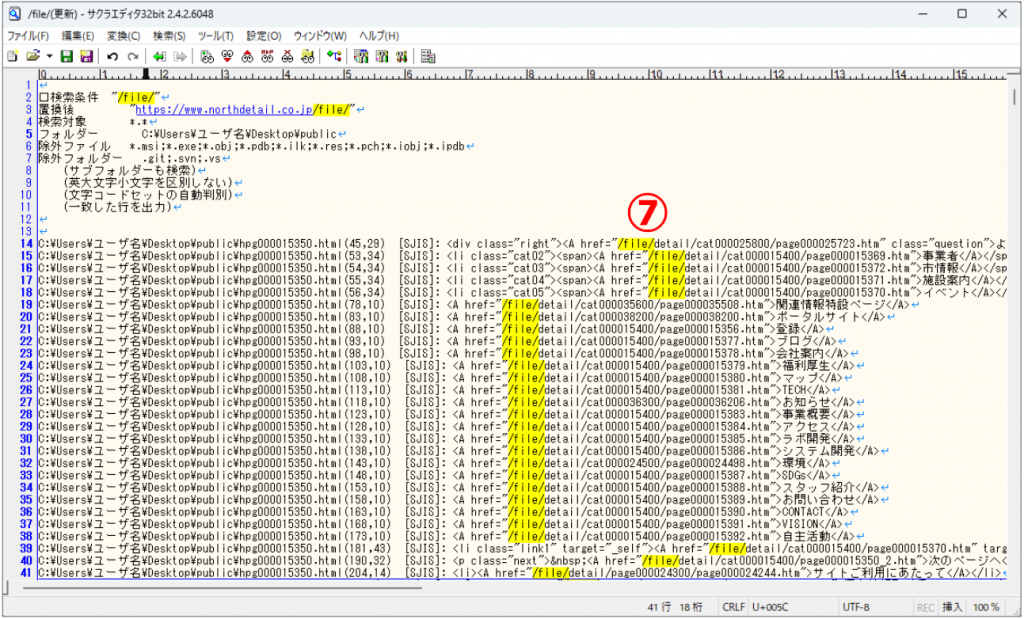
ファイルをエディタで開くと、「相対パス」が「絶対パス」に一括変換されているのが確認できました。
無事に8,000以上のファイルを一括で置換することができました。
おしまい。
Grep置換の存在を知ると、効率的に作業を進めることが気持ち良くなり、複雑な条件検索や置換も試したくなります。実務で使ったことがある正規表現を紹介します。
ただ、わたしはエンジニアではないので簡単な正規表現のみ紹介することにします。
サクラエディタでは、初期設定では正規表現は利用できないため、「正規表現」項目にチェックを入れます。
「任意の1文字」を表します。
「ワイルドカード(*)」のように「あらゆる文字」を表現するときに利用します。
例えば、正規表現の「1.2」で検索にマッチするのは、「132」「1あ2」「1@2」などです。
「1342」「1あい2」はマッチしません。ちなみに「12」もマッチしません。
「直前の文字の0回以上の繰り返し」にマッチします。
例えば、「12*34」で検索にマッチするのは、「1234」「122234」などです。さらに、「*」の直前の「2」の0回以上の繰り返しにマッチするため、「134」もマッチします。逆にマッチしないのは「34」「434」「1934」などです。
「34」がマッチしない理由は、「3」の前に「1」がないから。
「434」がマッチしない理由は、「3」の前に「1」がないから。
「1934」がマッチしない理由は、「1」と「3」の間に「2」以外の文字「9」があるから。
ちなみに、「2*」だとすべての文字がマッチしてしまうので注意です。2が「0回以上の繰り返し」なので、2がなくてもマッチしてしまいます。
ドット「.」とアスタリスク「*」は単体より、合わせて使うと便利です。
例えば、「12.*34」で検索にマッチするのは、「1234」「12234」「12934」「12あいうえお34」などです。
「12」と「34」に囲まれた文字を検索することができます。
「¥d」は10進数の1文字を表します。要するに「0~9」のいずれか1文字にヒットします。
例えば、「3月¥d日」で検索にマッチするのは、「3月3日」「3月9日」「3月0日」などです。逆にマッチしないのは「3月10日」「3月22日」などです。
「+」は「直前の文字の1回以上の繰り返し」にマッチします。「*」との違いは、直前の文字が必ず1回は必要という点です。
例えば、「3月¥d+日」で検索にマッチするのは、「3月3日」「3月21日」「3月321日」などです。また「3月1日」(大文字)もマッチします。
「^」は行頭であることを表します。
例えば、「^正規表現とは」で検索した場合は、「さて、正規表現とは」「 正規表現とは」のように行の頭に指定の文字列がないとマッチしません。あくまでも、行のはじめにあることが検索対象です。
「$」は行末であることを表します。
例えば、「です。$」で検索した場合は、「です」「である。」「です。 」のように行の末尾に指定の文字列がないとマッチしません。あくまでも、行末にあることが検索対象です。
Windowsでは「¥r¥n」は改行を表します。
よく利用するケースは、不要な改行を検索して削除する場合です。行頭の「^」と改行「¥r¥n」を合わせると、文字がない行を検索することができます。検索対象を「^¥r¥n」にして、置換対象を空にすれば、不要な改行を削除することができます。
| OS | 改行コード | 正規表現 |
| Windows | CRLF | ¥r¥n |
| Unix, Linux, MacOSX以降 | LF | ¥n |
Grep置換や正規表現という便利なものに1度触れてしまうと、常に効率化かできないかと考えてしまいます。面倒な作業を前にするとググって便利なツールをつい探すようになり、さらにラクすることを追求していくと結局はプログラムを学ぶ必要があるのか?と考えてしまうのです。
面倒を無くすためにプログラムを勉強する。。。それも大変ですね。。。



![]()



